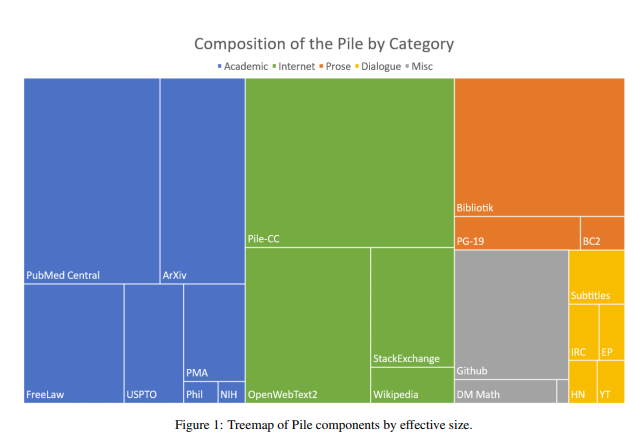
(or the Attraction for Complexity) There is a very common tendency in computer science and it is to complicate solutions. This complication is often referred as incidental/accidental complexity i.e. anything we coders/designers do to make more complex a simple matter. Some times this is called over engineering and stems from the best intentions :
Attraction to Complexity: there’s often a misconception that more complex solutions are inherently better or more sophisticated. This can lead to choosing complicated approaches over simpler, more effective ones.
Technological Enthusiasm: developers might be eager to try out new technologies, patterns, or architectures. While innovation is important, using new tech for its own sake can lead to unnecessary complexity.
Anticipating Future Needs: developers may try to build solutions that are overly flexible to accommodate potential future requirements. This often leads to complex designs that are not needed for the current scope of the project.
Lack of Experience or Misjudgment: less experienced developers might not yet have the insight to choose the simplest effective solution, while even seasoned developers can sometimes overestimate what’s necessary for a project.
Avoiding Refactoring: In an attempt to avoid refactoring in the future, developers might add layers of abstraction or additional features they think might be needed later, resulting in over-engineered solutions.
Miscommunication or Lack of Clear Requirements: without clear requirements or effective communication within a team, developers might make assumptions about what’s needed, leading to solutions that are more complex than necessary.
Premature Optimization: trying to optimize every aspect of a solution from the beginning can lead to complexity. The adage “premature optimization is the root of all evil” highlights the pitfalls of optimizing before it’s clear that performance is an issue.
Unclear Problem Definition: not fully understanding the problem that needs to be solved can result in solutions that are more complicated than needed. A clear problem definition is essential for a simple and effective solution.
Personal Preference or Style: sometimes, the preference for certain coding styles, architectures, or patterns can lead to more complex solutions, even if simpler alternatives would suffice.
Fear of Under-Engineering: there can be a fear of delivering a solution that appears under-engineered or too simplistic, leading to adding unnecessary features or layers of abstraction.
Agile has failed ? I don’t think so : https://medium.com/developer-rants/agile-has-failed-officially-8136b0522c49 Anything applied as a religion is doomed to fail and the same is for Agile. You can’t take any methodology and apply it “as is” to a company or project or dev-team; you need to adapt it and not make the company/team adapt to it. What I hope is that we don’t trow away the good ideas of Agile (iterations/continuous delivery, attention to technical excellence, simplicity (avoiding over engineering) just to mention a few).
Reasons why you burnout swe : https://engineercodex.substack.com/p/how-to-burnout-a-software-engineer My list in order of priority : 1. don’t ship code (there is nothing worse than working months on something that is not going to prod or is lingering in the deploy queue) 2. Not trusting your engineers by telling them in fine detail how to do things. 3. Lack of Recognition (not reward, about the difference).
From a friend of mine substack, Chris Hedges talking about war : “But these words give me a balm to my grief, a momentary solace, a little understanding, as I stumble forward into the void.”
Yoshua Bengio (CA) and John Bunzl (UK), moderated by Nico A. Heller on strengths and limitations of current artificial intelligence, why it may become a dangerous instrument of disinformation, why superintelligent AI may be closer (years) than most previously expected (decades) and how this could yield to catastrophic outcomes – from AI-driven wars to the extreme risk of extinction. https://www.youtube.com/watch?v=07c1ZRUQOeY. Notes, general concepts from Bengio talk :
AI currently perceive the world and make sense of it with images, sound and text, generating content in all 3 areas. Current systems are not at the level of human intelligence, they master what psychologist call system 1 intelligence (intuition) : react to any question/context, no reasoning (or little reasoning) – arithmetic : simple operations with numbers ok, more complex (of the type we will need paper and pencil) they make mistakes. System 2 intelligence : explicit reasoning, you can plan, imagine. Ex: driving left hand roads after having driven right hand all life. We take 1 hour to adapt because we don’t use intuition but reasoning. AI will get there : how much time will take to bridge the gap between s1 and s2 ? nobody knows, could be close or take 10 years. Training data currently needs to be filtered to remove data that appears to be insulting, homophobic or racists, dangerous, inadequate. AI will get there too to avoid the need of preparing training material. Machines that are as intelligent as we are will be inevitably more intelligent than us because they are machines : immortal, don’t sleep, can exchange info at high speeds like if they were a huge brain. Humans have culture to try to simulate this.
pure intelectual power, completely detached from the goal. The goal will make the difference between a “good” AI and an “evil” one.
humans cannot turn off compassion (or just most people can’t) as it has been hardwired into us by evolution; machines can
Stating a goal in a precise way is probably impossible so even AI with good goals might behave evil.
Goals are not expressable, we can only give partial specifications
We’ll get to the point where the game will be : who’s AI is bigger/better/faster ?
Most important thing to reduce the probability of bad behavior connected to AI is to reduce the actors, materials, information, proliferation (like we did for atomic bombs) Regulatory frameworks are necessary.
On crypto and thieves : “In February 2022, a hacker stole 120,000 wrapped Ethereum from Wormhole, a cross-blockchain bridge” https://newsletter.mollywhite.net/p/oasis-defi-centralization – subscribe to Molly White newsletter for unbiased crypto news.
Yes, I like Go programming language. I’m liking it so much that I have to resist from being a fan boy. I’m trying to understand where all this enthusiasm is coming from (I’m a seasoned coder) so here’s an attempt to find why :
Code readability — and maintainability — first, language features second
Integrated test environment : go test <package> executes all tests for the package. Unit testing features are builtin.
Code Coverage is builtin (with some limitations, for example if you use cgo it will not work).
Integrated tool chain : no need to have makefile at the cost of rigid hierarchy of data.
Exhaustive standard library containing everything you need to do server-side/network programming
Good Multi-threading features/model included in language (sync package, goroutines, channels), fast goroutines thanks to segmented stack implementation.
Basic set of OOP features, centered on composition, not inheritance : you won’t be able to mess up your code at the cost of not being perceived as an OO language by OO fanboys. For more details on whether go is oo or not go here.
Go is backed by some Famous Names in computing, and this inspires confidence.
CamelCase 🙂 ? Naaah, I hate camel case but I like the choice of having standard style, comments, indent; all supported by the language via go fmt package so that all code will look coherent.
So basically I like the fact that Go is a very opinionated language. You might like the single decisions or not but what I like most is that someone took care of taking them for you (so you don’t have to enforce them team wide or company wide)
Interesting read also on how and why go was born : quoting from Rob Pike speech at go conference SF 2012 :
“To put it another way, oversimplifying of course:
Python and Ruby programmers come to Go because they don’t have to surrender much expressiveness, but gain performance and get to play with concurrency.
C++ programmers don’t come to Go because they have fought hard to gain exquisite control of their programming domain, and don’t want to surrender any of it. To them, software isn’t just about getting the job done, it’s about doing it a certain way.
The issue, then, is that Go’s success would contradict their world view.
And we should have realized that from the beginning. People who are excited about C++11’s new features are not going to care about a language that has so much less. Even if, in the end, it offers so much more.”
New year is time for self-examination; one of the most frustrating things for a coder is writing code with bugs and bugs are almost always directly related to bad mental habits imho. This is not a complete list of any kind, it is a set of well known and widespread ones that you for sure have already encountered in your coder life. I’m writing them down just as a reminder for myself :
The “Let’s do it this way for now (I know this cannot be the final way of doing it), because I don’t want to stop 5 minutes and think about it” attitude. This is the worst of all bad habits in my opinion. It is this attitude that generates the most of production bugs because the only moment you had to focus on that specific issue you decided to skip over it, for the sake of continuity in your mental path (which is a good thing by itself but bad if not derogable ). That moment will never come again, that “preliminary” code will go strait to production and that issue will never ever be taken into account again until it generates a bug.
Using the “quick and dirty” way to do things even when there is no real need for that type of approach. This is related to the fact that we are almost always pushed to deliver fast and after time the “quick and dirty” approach becomes the standard one, always, regardless of requirements.
Unreadable code : this does not necessarily generate bugs but makes it difficult to fix them.It is caused by :
coder EGO : “nobody will ever be able to understand my code unless spending an hour over 10 lines”. I will be the only able to maintain it.
“This way is faster, (probably) ” (note probably, because nobody is ever measuring code speed). Modern compilers/cpus do things that we can’t imagine in terms of optimization, but “I can do better”.
Comment out unused code, or worse, gate it with a feature flag. Code that has no purpose is a major source of distraction and confusion. Today’s version control systems make it easy to revert any changes; there’s no reason not to remove dead code and other bloat.
Over engineering code or overdoing features : this one is so big that needs a separate post to handle it but we might try to summarize it with
One if my main tasks from 2015 on has been optimizing performance on various languages api (mainly C/C++). This post tries to recap best practices in this area.
For those like me who work in IT since the z80 let me say that cpu have changed, a lot; variability in computing time in modern computer architectures is just unavoidable; while we can guarantee the results of a computation we cannot guarantee how fast this computation will be :
Reasons for variance in computation time can be recap in :
Hardware jitter : instruction pipelines, cpu frequency scaling and power management, shared caches and many other things
OS activities : a huge list of things the kernel can do to screw up your benchmark performance
Observer effect : every time we instruments code to measure performance we introduce variance.
Also warming up the cpu seems to have become necessary to get meaningful results. Running hot instead of cold on a single piece of code is well described here https://youtu.be/zWxSZcpeS8Q?t=18m51s
You have to measure. There is no other way; things that by your experience might look faster if done in a certain way reveal to be slower when measured so put away all your preconceptions and prepare to A/B test your code for performance. Here’s are some hints, not a complete list at all :
1) make sure your code is doing what you expect. Profile your code compiled without the optimizer and check that your are not calling unwanted code (valgrind/kcachegrind for profiling)
2) measure/time your code : I use linux/c this code for duration, gnu scientific library (libgsl) for related math. Check out chrono for c++ and/or google benchmark for a complete framework.
3) as mentioned above warm up the cpu with your code before measuring by running your code a large number of times. Measure the execution time average of a large number of runs. Ideally your measure is good when results have “normal” distribution. Narrow the code you measure until you get normal distributed results.