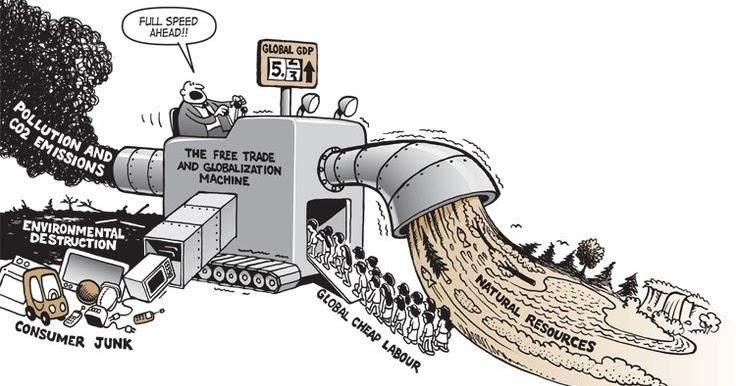
“I believe we should not consider AI safe. A critical event that may result in the extinction of Homo sapiens is possible, but the danger is not in open models, or China making faster progress than the US. The danger is that a few CEOs (everywhere in the world) without the required background and legitimacy are in the position of making hard choices for humanity at large. They were not selected to do so; it was just the randomness of events that created this setup. They can’t speak for everybody, given the stakes, just because they have GPUs and money. This is the first thing that should be fixed.” : antirez on ai safety https://antirez.com/news/172
Perfection has a bad rep in the industry, and it’s often conflated with overengineering. Perfection was never the enemy. Ambiguous requirements were. Get those right, get every constraint on the table, and the perfect solution stops being a fantasy. It becomes the only thing left standing.
https://var0.xyz/posts/perfection-is-not-over-engineering.html
DwarfStar is a small native inference engine optimized first for DeepSeek V4 Flash : https://github.com/antirez/ds4/tree/main
llm open models ecosystem : Ollama for easy local running, Hugging Face as the de facto distribution hub, vLLM for production serving, LoRA tooling for fine-tuning.
Tokenizer with a GUI : https://tiktokenizer.vercel.app/?model=meta-llama%2FMeta-Llama-3-8B
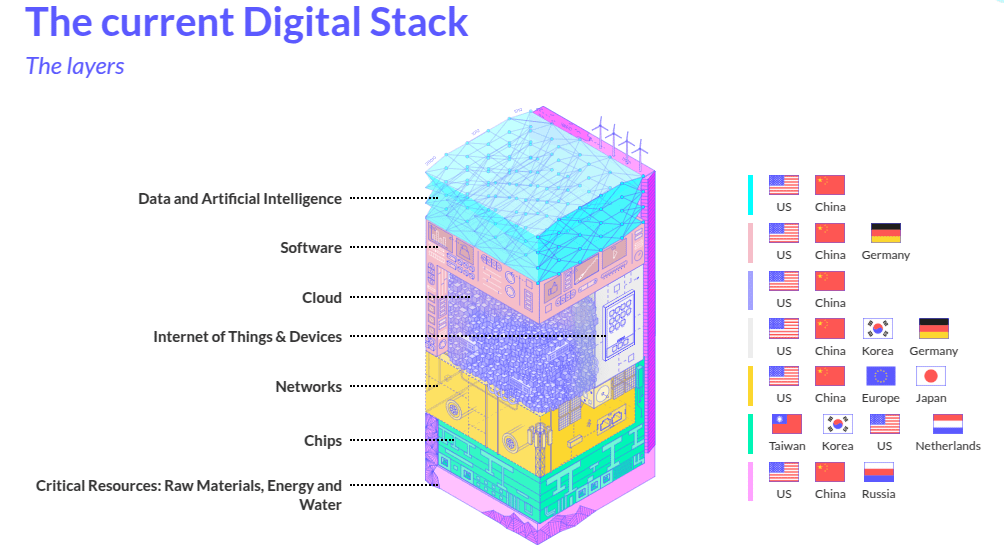
Also math is under pressure :
This declaration calls for action to address the challenges posed by the use of artificial intelligence within mathematics research. It is the result of a community initiative and is endorsed by the International Mathematical Union (IMU). https://leidendeclaration.ai/
curl dev team under pressure : https://daniel.haxx.se/blog/2026/05/26/the-pressure/
“The loop looks like this: a human poses a question; a model proposes candidates; a verifier filters the candidates; a human curates what survives. Round and round. What Stappers and Claude did is not fundamentally different in shape from what Tao and Lean are doing, or what the GNoME pipeline does in materials science, or what AlphaFold did for protein structure. The shape is the same. The loop does the discovery.“
https://blog.apiad.net/p/ai-is-doing-something-weird-to-science
Magnifica Humanitas https://www.vatican.va/content/leo-xiv/en/encyclicals/documents/20260515-magnifica-humanitas.html
“Claude’s Constitution : our vision for Claude’s character” : https://www.anthropic.com/constitution
Reticulum is the cryptography-based networking stack for building local and wide-area networks with readily available hardware https://reticulum.network/
European Digital Wallet: The Normalization of Systemic Risk : https://www.eclaireur.eu/p/podcast-european-digital-wallet-the
Github compromised : https://www.aikido.dev/blog/github-breached-vs-code-extension
https://thehackernews.com/2026/05/github-investigating-teampcp-claimed.html
“Il modello linguistico è una cuoca che ha letto tutti i ricettari del mondo e ha cucinato un sacco di volte, ma non ha mai mangiato” https://koselig.substack.com/p/koselig-217-ne-fatine-ne-pappagalli
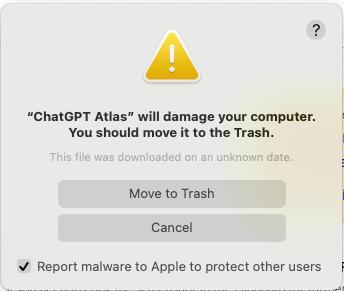
Apple declares war to ChatGPT Atlas ?
Extract structured records from any file — PDFs, contracts, photos, receipts, scans, images. Filter, aggregate, and query with API, SDK, or MCP. No templates. No layout rules. https://sifter.run/
Latest Linux LPE, 1 hour of AI work on linux crypto api ..
https://copy.fail/
The Abstraction Fallacy: Why AI Can Simulate But Not Instantiate Consciousness https://deepmind.google/research/publications/231971/
Right to repair https://www.thedrive.com/news/john-deere-to-pay-99-million-in-monumental-right-to-repair-settlement
Claude Is Not Your Architect. Stop Letting It Pretend. https://www.hollandtech.net/claude-is-not-your-architect/
Developers vs. Users perspective

Evaluating and mitigating the growing risk of LLM-discovered 0-days https://red.anthropic.com/2026/zero-days/
Claude’s Cycles, Don Knuth, Stanford Computer Science Department
(28 February 2026; revised 16 March 2026)
Shock! Shock! I learned yesterday that an open problem I’d been working on for several weeks had just been solved by Claude Opus 4.6— Anthropic’s hybrid reasoning model that had been released three weeks earlier! https://www-cs-faculty.stanford.edu/~knuth/papers/claude-cycles.pdf
The adtech world is preparing for #aifirst internet : https://github.com/IABTechLab/CoMP/blob/dev/CoMP-1.0.md
The Open Licensing Standard for AI Crawlers – Giving publishers a voice and AI a smarter path forward — beyond scraping vs. paywalls to balanced collaboration https://peekthenpay.org/#how-it-works expect one of these new standards per month for the next months.
How AI internet scraping is evolving, current techniques used :
– Direct HTTP Crawlers (Traditional Crawlers) : GPTBot, ClaudeBot, Meta-ExternalAgent, Google-Extended, Bytespider, Amazonbot, Applebot-Extended, CCBot
– Cloud Browser Infrastructure (Browser-as-a-Service) : Browserbase, Hyperbrowser
– Web Scraping & Data Extraction Platforms : Firecrawl, Apify, Zyte
– Browser-driven web agents : Comet (Perplexity), Dia (The Browser Company)
– Real-Time Fetchers (On-Demand) : ChatGPT-User, OAI-SearchBot, Claude-User, Perplexity-User
Tollbit state of the bots : https://tollbit.com/bots/25q2/

Really simple licencing : The open content licensing standard
for the AI-first Internet https://rslstandard.org/
Vibe Coding Without System Design is a Trap : https://www.focusedchaos.co/p/vibe-coding-without-system-design-is-a-trap